Global Data and Web Scraping
Data is quickly becoming the currency of the emerging digital economy. As digital transformation efforts proliferate and become commonplace, data will take center stage as a critical driver of these initiatives. Organizations that are able to mobilize their data assets to power critical business initiatives will see a distinct advantage in the years to come.
The Distil Networks’ report claims that about 2% of the revenue that businesses make is lost due to web scraping. Although it is difficult to put the global online revenue accurately in figures, the online statistics company Statista reports that online retail sales in the year 2015 were more than $1.5 trillion. 2% out of the $1.5 trillion make a staggering $30 billion loss.
In these modern and high-tech times, traditional methods of extracting data from the Web are slowly but surely fading out. ‘Cutting and Pasting” data extraction techniques in the majority of industries are replaced with more modern and technologically sophisticated solutions that bring faster and better results. An excerpt taken from a 2014 report “Website Scraping” available on happiestminds.com, states some of the main issues with the traditional “Cutting and Pasting” way of data extraction. Firstly companies can’t measure cost efficiency and it itself can escalate very quickly. Secondly, each manual data extraction is known to be error-prone. Lastly, the whole process of cleaning up the data is expensive and time-consuming, especially when there are massive volumes of data. As it is stated in a 2015 EPSI (European Public Sector Information Platform) report Web Scraping: Applications and Tools, the volume of digital content in 2015 was estimated at 7.9 zettabytes of data. It furthermore states that almost 90% of the world’s data has been created over the past two years. One can only imagine how long would it take for a person to barely scrape the top of this mountain of data, in terms of traditional “Cut and Paste” data processing.
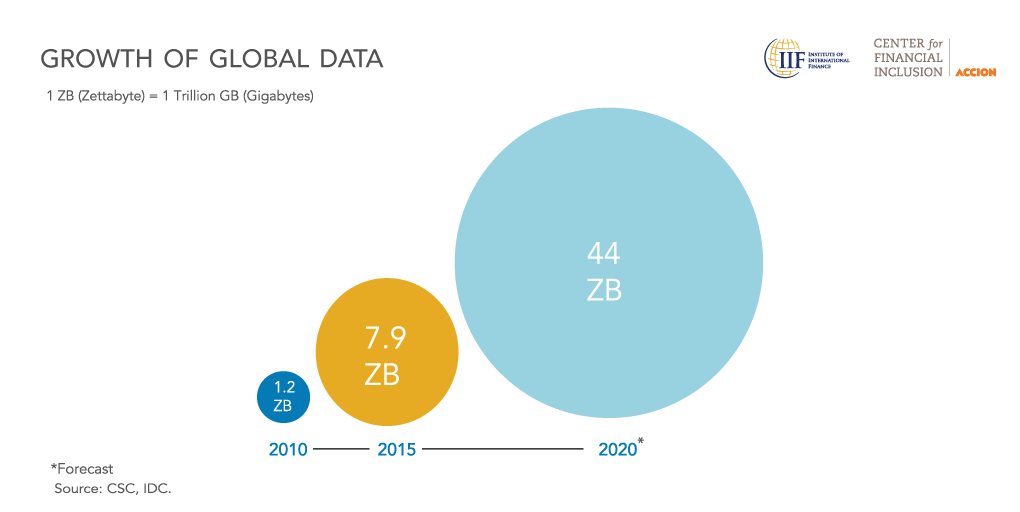
The picture taken from Center for Financial Inclusion website, displays the volume of data generated in the year 2010 and 2015 which was 1.2 billion zettabytes and 7.9 billion zettabytes respectively. The global annual data generation is estimated to grow more than double annually in the foreseeable future, reaching 44 zettabytes by 2020, according to IDC.
But with the application of data and web scraping, transforming unstructured website data into a database for analysis or repurposing content into the web scraper’s own website and business operations, companies have gained open access to massive amounts of specific information from specific websites. In Web Scraping Trends for 2017, web scraping is considered an indispensable resource when a company is trying to gain a competitive edge via using business intelligence. This helps companies ascertain who their competitors are, determine what their target market is, and most importantly improve the consumer’s satisfaction.
Source: bizzbeesolutions.com